- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English

Mit ChatGPT ist das Thema der künstlichen Intelligenz in den Medien aktueller denn je. Kaum jemand außerhalb der Informatik kann jedoch von sich behaupten, zu wissen wie eine KI wirklich funktioniert. Mit der folgenden Blaupause wollen wir ein wenig Licht in die vermeintlich "superschlaue" Black-Box des Maschinellen Lernens bringen. Hierzu nutzen wir die EDGE-AI Blöckchen in unserer IoT2-Werkstatt. Der Begriff EDGE-AI steht für künstliche Intelligenz im Endknoten, d. h. bei uns findet das maschinelle Lernen energieeffizient und datensparend direkt im Octopus statt.
Unsere KI-Aufgabe:
Gut schmeckende Äpfel anhand der Farbe von schlecht schmeckenden Äpfeln unterscheiden. Eine ähnliche KI finden wir z. B. bei Amazon Fresh, um die Haltbarkeit von Lebensmitteln schon vor dem Transport zum Kunden abzuschätzen (s. Video unten).
Oder schauen wir in die Personalabteilung von großen Firmen. Dort gibt es im Kontext der Personalakquise eine analoge Aufgabe: Gute (wohlschmeckende) Bewerber anhand der Bewerbungsmappe von ungeeigneten Bewerbern unterscheiden.
Wir werden dazu einen sogenannten „Nächste-Nachbarn-Klassifikator“ verwenden. Dieser benötigt eine Lernstichprobe (Trainingsdaten) in Form von Äpfeln, die wir angebissen haben und deren Merkmale und Eigenschaften wir kennen. Bzw. Personen, die wir eingestellt haben und deren Leistung wir beurteilen können.
Bei unserem Algorithmus handelt es sich um ein Verfahren des überwachten Lernens (englisch supervised learning), bei dem wir Eingang (Merkmale) und Ausgang (Eigenschaften) kennen und schließlich einen Algorithmus trainieren, der anhand der Eingänge auf den Ausgang schließt.
Ein Nächster-Nachbar-Klassifikator bestimmt in der dem Training anschließenden Anwendungsphase die Merkmale eines neuen unbekannten Bewerbers und schaut in der Liste der Trainingsstichprobe, welcher Trainingdatensatz diesem in den Merkmalen am nächsten kommt. Auf Basis dessen im Training ermittelten Eigenschaften wird nun eine Prognose für die Eigenschaften des neuen, unbekannten Apfels ausgegeben.
Aber genau so machen wir es doch auch, wenn wir im Supermarkt einen Apfel auswählen. Wir erinnern uns an den Geschmack der roten Äpfel die wir bereits gegessen haben (der Trainingsstichprobe) und greifen zu.
Die erste anfassbare KI ist entstanden. Testen kann man den Algorithmus prima an einem Beutel wohlschmeckender roter Äpfel und einem Satz grüner Viezäpfel (sauer).

Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an Youtube/Google übermittelt. Weitere Informationen dazu finden Sie unter Google Privacy.
Um den Algorithmus anfassbar zu gestalten, benötigen wir zuerst eine Online-Erfassung der Merkmale. Dies können z. B. das Gewicht, der Durchmesser oder die Farbe sein. In unserem Fall kommt ein RGB-Sensor APDS-9960 (Alternative) zum Einsatz. Dieser ermittelt die Farbe unseres Apfels, indem er sie in die drei Spektralkanäle Rot (R), Grün (G) und Blau (B) zerlegt. Die Intensität dieser drei Kanäle sind also die Merkmale unseres Apfels. Natürlich leuchtet der Apfel nicht von selbst, sondern wir benötigen Umgebungslicht zur Messung. Hier ist auf konstante Lichtverhältnisse zu achten (oder eine weiße LED zur Messfeldbeleuchtung zu integrieren, s.u.).
Als User-Interface zur Bedienung und Eingabe der Eigenschaften nutzen wir die CharliePlex LED Matrix und einen Drehencoder (z.B. diesen).
Das dazugehörige Ardublock Programm findet sich im ZIP-File im Ordner Beispiele unter "MINT macht Mut" und hier.


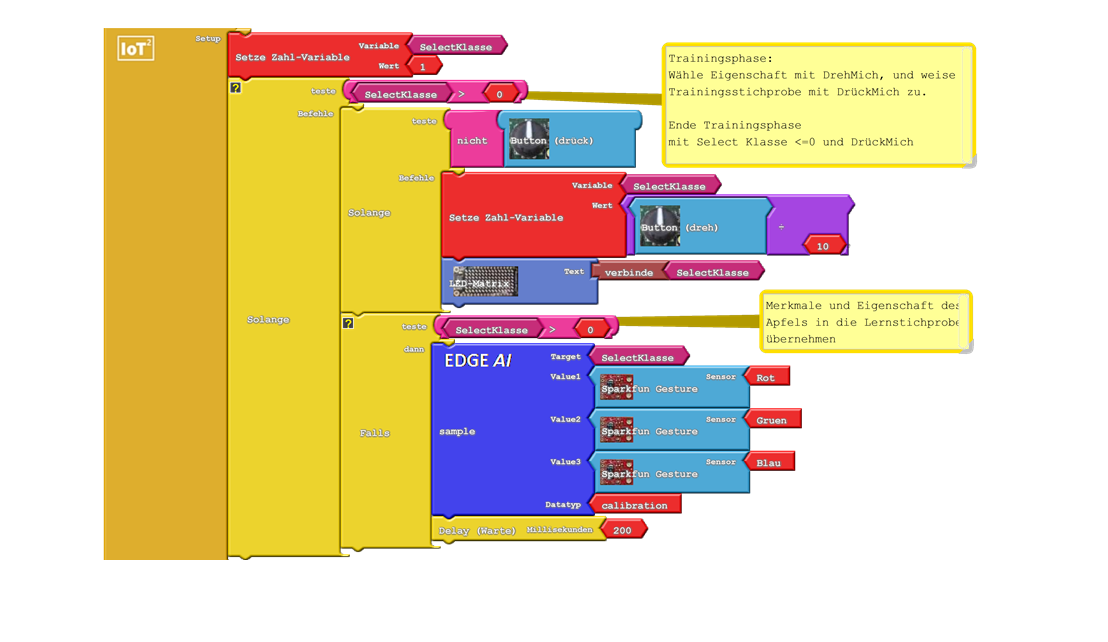
In der Trainingsphase ermitteln wir Ein- und Ausgang der zur Lernstichprobe gehörenden Äpfel. Die Funktionsweise ist relativ simpel: Wir halten den Apfel vor den Sensor und weisen ihm durch Drehen des Encoders eine Geschmacksklasse zu. Diese speichern wir in einer Variable SelectKlasse. Zusätzlich geben wir diese über die LED-Matrix aus. Beim Drücken des Tasters wird der Wert von SelectKlasse abgefragt. Ist dieser größer als 0, so übernehmen wir die ausgewählten Informationen in die Lernstichprobe – fügen also einen Merkmalsvektor in Form der drei Farbkomponenten und ein durch Anbeißen gelerntes Ergebnis (Eigenschaft Geschmack als Schulnote zwischen 1 und 6) hinzu.
Diese Lernstichprobe wird anschließend in der Anwendungsphase genutzt, um die Äpfel nach ihrem Geschmack zuklassifizieren. Dabei ist:
Wir vergeben für alle Äpfel der Lernstichprobe eine Geschmacksbeurteilung. Damit erweitern wir unser Datenfeld um weitere Elemente. Die Daten der n Elemente der Lenstichprobe können wir nun – etwa mit Geogebra 3D – visualisieren.




Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an Youtube/Google übermittelt. Weitere Informationen dazu finden Sie unter Google Privacy.
In der Anwendungsphase können wir die Eigenschaften (Geschmack) eines neuen, unbekannten Bewerbers bzw. Apfels prognostizieren. Hierzu nutzen wir einen sogenannten Nächste-Nachbarn-Klassifikator. Dieser entscheidet anhand unserer Trainingsdaten und den aktuellen Merkmalen, ob ein Apfel schmeckt oder nicht. Der Algorithmus ist sehr einfach, wir brauchen nur im Merkmalsraum zu schauen, welcher Apfel der Trainingsstichprobe unserem Apfel am nächsten kommt und schließen dann von diesem nächsten Nachbarn direkt auf die Eigenschaften des unbekannten Apfels. Optisch ist uns das sofort klar, mathematisch können wir das als euklidischen Abstand im Raum der Merkmalsvektoren bestimmen.



Hier wird auch der Begriff „Bias in der KI“ klar: Haben wir in den Trainingsdaten nur grüne Viezäpfel, so wird ein Golden Delicious, d.h. ein wohlschmeckender grüner Apfel bei der Bewerbung keine Chance haben. Jedes Mal ist ihm ein grüner Viezapfel in der Farbe am ähnlichsten, er wird als sauer aussortiert (und nicht zum Bewerbungsgespräch eingeladen). Die KI ist rassistisch, d.h. besitzt in den Trainingsdaten begründete Vorurteile. Abhilfe: Trainingsdaten repräsentativ wählen (mit Golden Delicious).
Natürlich stehen wir dann vor dem Problem, einen wohlschmeckenden grünen Apfel von einem ungeniessbaren grünen Viezapfel zu unterscheiden. Ein wichtiges Kriterium ist sicher die Größe. Dazu benötigen wir einen weiteren Sensor, vielleicht eine Waage oder eine Abstandsmessung zur Durchmesserbestimmung. Da unser Ardublock nur drei Merkmale gestattet, würden wir dann den blauen RGB-Kanal ersetzen.
Um die Farberkennung zu verbessern, kann der RGB-Sensor mit einer eigenen Beleuchtung ausgestattet werden. Eine Anleitung findet sich hier. Die Druckdatei für das Gehäuse hier. (Quelle IP-Projekt: S. Sohrabi, A. Harwardt).
Unser EDGE-KI Block sehr universell. Ersetzen wir die RGB-Kanäle durch den VOC Sensor des Octopus (BME 680), so können wir z.B. Getränke am Geruch erkennen. Siehe künstliche Nase im COSY-Projekt. Der einzige Nachteil, wir müssen bei jedem Neustart die Lernstichprobe erneut aufbauen, d.h. die Trainingsphase durchlaufen. Im Falle einer realen Anwendung würde man dies allerdings nur einmalig durchführen und das Datenfeld dann speichern.
Oben haben wir gesehen, dass sich rote und grüne Äpfel im 2D-Merkmalsraum einfach über eine Gerade (also linear) trennen lassen. Im Profibereich finden häufig leistungsfähigere Kassifikatoren wie z. B. die Support Vector Machine oder künstliche neuronale Netze ihren Einsatz, die auch nicht linear trennbare Klassen separieren. Diese lassen sich in einer EDGE-Variante auch auf eingebetteten Systemen nutzen. Hierzu sei auf die Cloud-Anwendung EDGE-Impulse verwiesen, zu deren Unterstützung es weitere Blöckchen im KI-Baukasten der IoT2-Werkstatt gibt.

Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an Youtube/Google übermittelt. Weitere Informationen dazu finden Sie unter Google Privacy.
Sie verlassen die offizielle Website der Hochschule Trier